SigLIP: Sigmoid Loss for Language Image Pre-Training
Background
VLP의 진화 과정
Transformer가 발전함에 따라 대량의 데이터로 사전 학습하는 모델이 부각되고 있습니다. Pre-training 모델을 학습하고 Downstream Task 성능을 개선하는 방법은 Multimodal Learning의 초점이 되고 있습니다.
CLIP (Contrastive Language-Image Pre-training)
Encoder base모델로 이미지(ViT)-텍스트(BERT)를 Contrastive Learning하는 것이 핵심입니다. 웹에서 직접 4억개의 데이터셋을 만들어 학습시키고 Zero-shot 성능이 뛰어나다는 것이 특징입니다. 링크
BLIP (Bootstrapping Language-Image Pre-training)

Text generation, Image-text retrieval task를 모두 잘하는 새로운 모델 구조(MED)가 등장했습니다. 이 연구에서는 CapFilt를 통해 web data의 noisy caption 문제 해결했다는 특징이 있습니다. 링크
BLIP-2 (Bootstrapping Language-Image Pre-training)
Frozen model간의 modality gap을 메우기 위한 Q-Former라는 새로운 방법을 제시 했습니다. Trainable Parameter 개수를 줄여 학습 효율성을 높이고, Multimodal 챗봇의 가능성을 보여준 연구입니다. 링크
기존 연구의 장점과 단점
장점
- 인터넷을 크롤링하여 이미지-텍스트 쌍 데이터 세트를 수집하는 것이 비교적 저렴합니다.
- Downstream task(예: 이미지 분류/검색)으로의 Zero-shot이 가능합니다.
- 성능은 모델 및 데이터 세트 크기에 따라 확장됩니다.
- 즉, 더 큰 네트워크와 데이터 세트일수록 더 나은 성능을 보여줍니다.
단점
- Contrastive Learning을 사용하기 때문에 대규모 배치 크기가 필요. 많은 GPU가 필요한 32K 배치 크기를 사용(CLIP 연구)
- 결론적으로 GPU 간에 많은 통신이 필요하기 때문에 Bottleneck이 발생합니다.
(추가) Contrastive Learning 연산 과정
모든 positive pair의 유사도는 모든 negative pairs로 정규화됩니다. 따라서 모든 GPU는 모든 쌍별 유사도에 대해 NxN 행렬을 유지하고 있어야 됩니다. 이는 매우 큰 O(n²) 시간 복잡도를 가지게 된다는 문제가 있습니다.
(추가) Contrastive Learning이 큰 배치사이즈가 필요한 이유
CL은 많은 샘플 쌍에서 올바른 쌍과 잘못된 쌍을 비교하여 학습하는 방법입니다. 배치 크기가 클수록 더 많은 비교를 할 수 있어, 손실 함수가 더 풍부한 정보를 바탕으로 gradient를 계산할 수 있습니다. CLIP에서는 softmax 함수를 사용하여 이미지와 텍스트 쌍 간의 유사도를 확률로 변환합니다. 이때 큰 배치 크기는 softmax 계산의 분모를 크게 만들어, 각 샘플 간의 유사도 차이를 더 명확하게 구분할 수 있습니다.
따라서 CLIP의 배치 크기 요구 사항을 줄이기 위한 방법인 SigLIP이 제안됐습니다.
Method
Softmax 함수 대신 Sigmoid 함수를 사용합니다.
SigLIP는 비대칭적이지 않으며 전역 정규화 인자도 필요하지 않습니다. SigLIP는 시그모이드 연산을 사용하고 각 이미지-텍스트 쌍(양수 또는 음수)은 독립적으로 평가됩니다. 따라서 모든 GPU가 모든 쌍별 유사도에 대해 NxN 행렬을 유지할 필요가 없습니다.
Sigmoid loss pseudo-implementation
우선 정규화된 text, image 표현을 내적하여 각 logits을 구합니다. 이후 대각선 값이 1, 나머지를 -1로 만든 label을 통해 element-wise multiplication로 각 값을 계산합니다. 결론적으로 Sigmoid 함수로 Contrastive Learning과 유사한 효과를 낼 수 있습니다.
With one little detail: add a learnable bias, much like the temperature.
Chunked 구현 제안
CLIP은 모든 GPU 간에 이미지와 텍스트 feature를 모두 전달하여 NxN 정규화 행렬을 계산합니다. 따라서 두 번의 전체 수집 작업이 필요합니다.
하지만 image feature를 고정하고 SigLIP은 모든 GPU 간에 text feature만 전달하여 모든 쌍별 유사도를 계산합니다. 따라서 단일 전체 수집 작업이 필요
하지만 여전히 모든 feature를 수신할 때까지 상태를 유지하기 때문에 여전히 비쌉니다. 따라서 청크 단위로 연산하는 것이 제안됩니다.
Chunked Example
논문에서 3개의 GPU에 분산된 크기 12의 미니 배치인 설정을 사용하여 이 아이디어를 보여줍니다.
초기 상태 -> 부분 손실 계산 -> 텍스트 표현 교환 -> 전체 손실 계산과정을 통해 구현됩니다.
a. 각 장치(GPU)는 4개의 이미지 표현과 4개의 텍스트 표현을 가지고 있습니다.
b. 각 장치는 자신이 가지고 있는 이미지와 텍스트 표현을 바탕으로 부분적인 손실을 계산합니다.
c. 텍스트 표현이 장치 간에 교환되고, 새로운 손실을 이전 손실에 더합니다.
d. 모든 이미지와 텍스트 쌍이 상호작용하도록 반복 후 합산하여 최종 손실을 계산합니다.
Experiments
Contrastive Learning & Sigmoid Loss
SigLIP은 작은 배치 크기(예: 4~8k)에서 CLIP보다 우수한 성능을 달성합니다. 관련 문헌에서는 큰 배치 크기가 성능을 향상시킨다고 주장하지만, 이 연구에서는 SigLIP과 CLIP 모두 32k 배치 크기에서 포화 상태에 도달하는것을 확인했습니다.
Locked image Tuning (LiT)
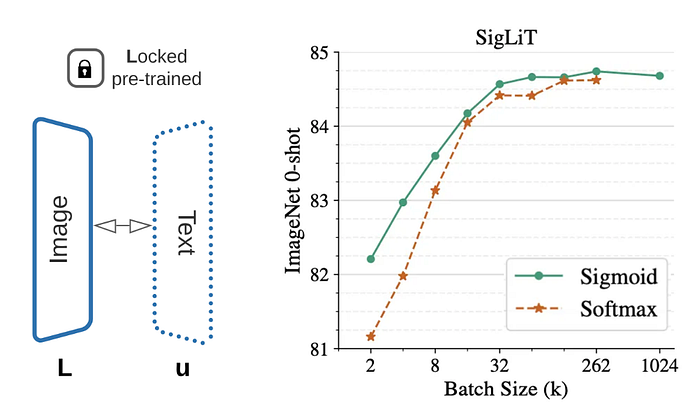
이미지 인코더를 처음부터 학습하는 것은 비용이 많이 들기 때문에 사전 학습된 이미지 인코더를 활용하는 방법입니다. 사전 학습된 이미지 인코더를 로드하고 사전 학습 중에 모델의 가중치를 frozen시킵니다. LiT는 사전 학습 중에 텍스트 인코더의 가중치만 계산하기 때문에 CLIP에 비해 비용이 상당히 낮습니다. 이 방법을 쓰면 확실히 Softmax 방법보다 더 좋은 성능을 보여줍니다.
mSigLIP: Multi-lingual pre-training
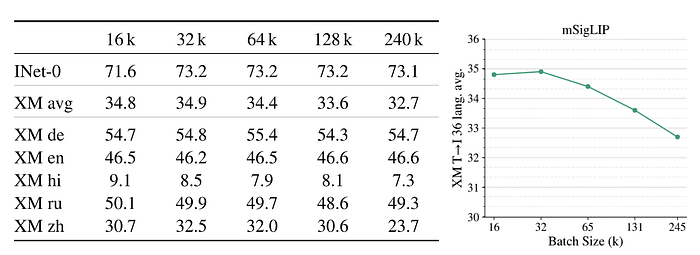
mSigLIP 모델은 WebLI 데이터셋의 100개 언어를 사용하여 학습 데이터를 확장했습니다. 100개 이상의 언어를 사용하는 다국어 환경에서 32K 배치 크기가 성능 면에서 충분하다는 것을 발견했습니다. 이는 36개 언어를 사용하는 교차 모달 검색 작업에서 특히 두드러집니다.
SigLiT ImageNet 0-shot transfer
0-shot transfer는 해당 라벨을 학습하지 않은 상황에서 몇개의 예시만 학습시켜서 성능을 전이하는 방법입니다. 이 방법에서는 큰 배치 사이즈를 사용하는 것이 더 효과적입니다. 큰 배치사이즈에서도 Sigmoid Loss 학습이 Softmax(Contrastive Learning)보다 성능이 더 좋습니다.(+효율도 좋다)
SigLIP with pre-trained encoders (Image & Text)
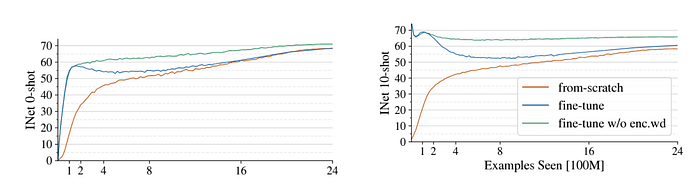
Encoder를 처음부터 학습하는 것(from-scratch) 보다 학습된 Encoders를 사용하는 것이 효과적입니다. 이 과정에서 Weight Decay(정규화)를 사용하게 되면 성능이 저하되는 것을 발견했습니다. 따라서 Pre-trained Encoders를 사용하여 Weight Decay 없이 Fine-tuning 하는 것이 효과적입니다.
The Effect of Batch Composition
다양한 배치 구성을 통해 각 설정에서의 모델 성능을 평가했습니다. 불균형한 배치 구성(예: 1:16k)이 성능에 치명적이지는 않다는 것을 관찰했습니다. 따라서 효율적인 부정 예제 마이닝 전략이 모델의 성능을 향상시킬 수 있음을 확인했습니다.
Sigmoid-training increases robustness to data noise
Image-Text Pair 데이터는 대부분 웹에서 크롤링 되기 때문에 Robustness가 중요합니다. 다양한 방법으로 노이즈를 포함한 데이터셋에서 Sigmoid 방법이 지속적으로 더 좋은 성능을 보여줍니다.
Conclusion
- 이 연구는 Sigmoid함수를 활용한 효율적인 Language-Image Pre-Training 방법 제시했습니다.
- Sigmoid Loss를 사용하여 메모리 효율성을 크게 향상시켰습니다.
- 여러 벤치마크에서 기존 모델들을 능가하는 성능을 보여줍니다.
- 기존 방법보다 robustness를 향상시켰습니다.
- 결론적으로 VLP의 메모리 요구사항을 크게 감소시켰습니다.
