Taewan ChoMARLIN: Multi-Agent Reinforcement Learning Guided by Language-Based Inter-Robot Negotiation본 논문에서는 Multi-Agent Reinforcement Learning guided by Language-Based, Inter-Agent Negotiation (MARLIN)이라는 새로운 방법을 제안합니다. 이 방법은 에이전트가 자연어…Feb 9Feb 9
Taewan ChoMulti-Agent Consensus Seeking via Large Language Models본 연구에서는 다중 에이전트 시스템의 핵심 문제 중 하나인 합의 도달(consensus seeking) 문제를 다룹니다. 여러 LLM이 동일한 문제를 해결하기 위해 협력할 때, 초기에는 서로 다른 해결책을 제시할 수 있지만, 지속적인 협상을 통해…Jan 28Jan 28
Taewan ChoRS-Agent: 원격 탐사 자동화 에이전트원격 탐사 기술의 급속한 발전 덕분에 매일 수십 테라바이트의 고해상도 이미지를 획득할 수 있게 되었고, 이러한 이미지는 재난 감지, 환경 모니터링, 도시 계획 등 사회 경제적 환경의 다양한 측면에 원활하게 통합되었습니다.Dec 5, 2024Dec 5, 2024
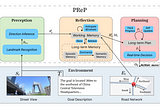
Taewan ChoPerceive, Reflect, and Plan: LLM을 활용한 경로찾기이 연구는 도시 환경에서 목표 지향적인 에이전트 내비게이션 문제를 다룹니다. 즉, AI 에이전트가 잘 알려진 랜드마크와 관련된 목표 위치에 대한 언어적 설명만 제공받고, 주변 장면 관찰(랜드마크 인식 및 도로망 연결 포함)을 통해 명시적인 지시 없이…Dec 1, 20241Dec 1, 20241
Taewan ChoReflexion: 스스로 성찰하고 개선하기목표 지향적인 에이전트는 trial-and-error와 같이 기존 강화 학습 방법처럼 광범위한 훈련 샘플과 비용이 많이 드는 finetuning 이 필요합니다. 그래서 저자들은 가중치를 업데이트하는 대신 언어적 피드백을 통해 언어 에이전트를 강화하는…Oct 28, 2024Oct 28, 2024