Jun 16, 2024
14 stories






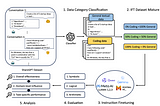





Transformer에 대항하는 새로운 아키텍처 Mamba
Transformer가 정답이 아닐 수 있다는 것을 보여준 새로운 이론
Classification 모델을 더 효율적으로 학습시기 위한 방법


기존 MoE에서 더 나아가 연산 최적화를 시키는 방법


Token choice routing MoE 방법의 단점을 개선시킨 Expert choice routing


Multi-head attention의 성능을 개선시키기 위해 등장한 GQA


현대 NLP의 가장 기본이 되는 모델 Transformer


Attention의 연산 과정을 수학적 트릭을 사용하여 10배 개선시킨 Flash Attention


Mar 13, 2024
